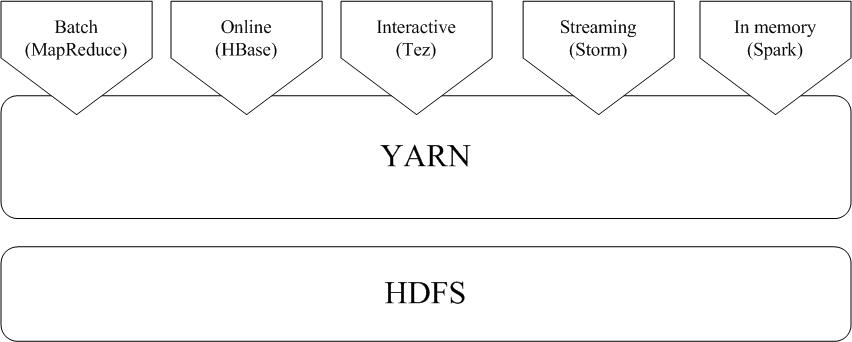
简介
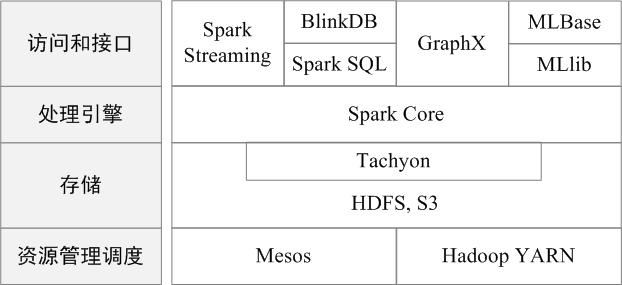
Spark 专注于数据的处理分析,而数据的存储还是要借助于 Hadoop 分布式文件系统 HDFS、Amazon S3 等来实现的
运行架构
基本概念
- RDD:弹性分布式数据集(Resilient Distributed Dataset)
- DAG:有向无环图
- Executor:运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据
架构设计
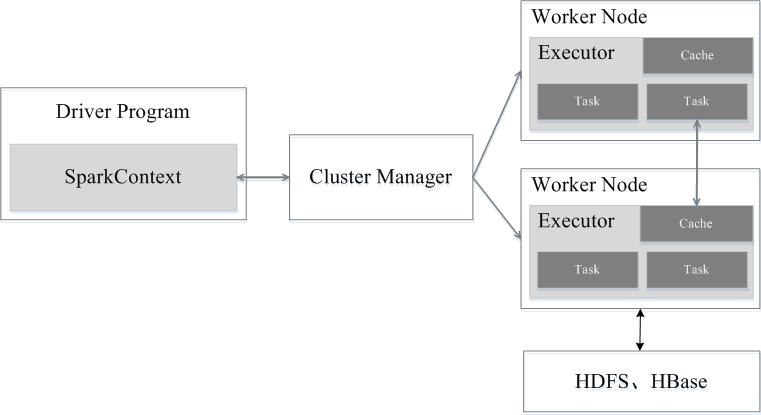
Spark 运行架构包括
- 集群资源管理器(Cluster Manager)
- 运行作业任务的工作节点(Worker Node)
- 每个应用的任务控制节点(Driver)
- 每个工作节点上负责具体任务的执行进程(Executor)
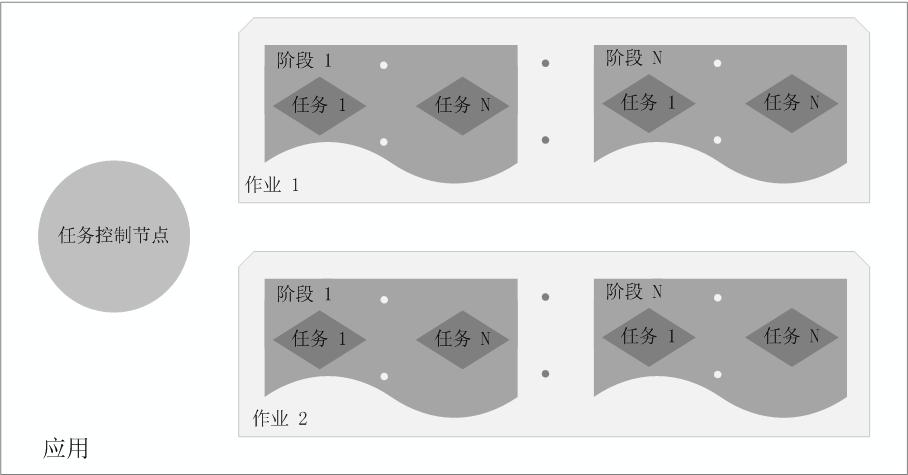
一个应用(Application)
- 一个任务控制节点(Driver)
- 若干个作业(Job)
- 一个作业由多个阶段(Stage)构成
- 一个阶段由多个任务(Task)组成
- 一个作业由多个阶段(Stage)构成
Spark 运行基本流程
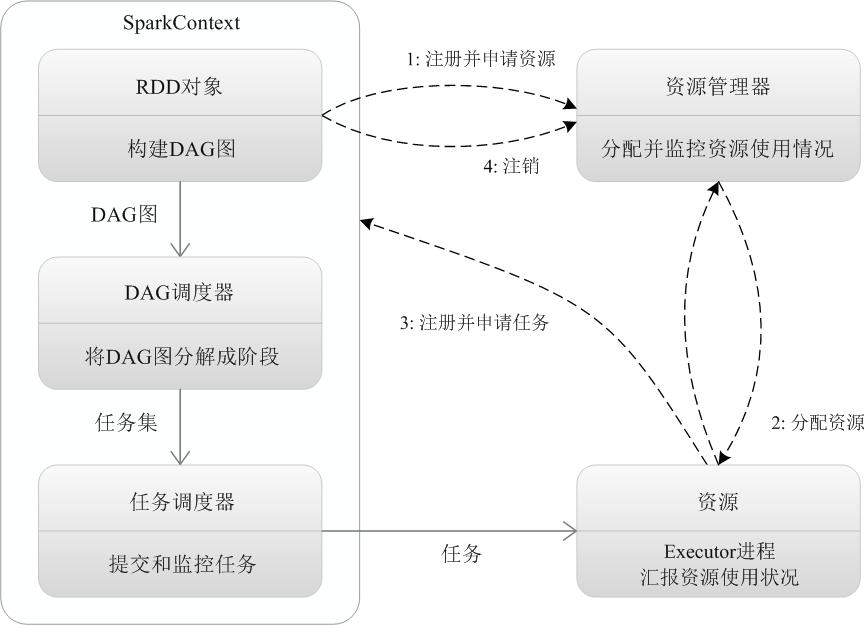
特点:
- 每个应用都有自己专属的 Executor 进程
- 只要能够获取 Executor 进程并保持通信
- Executor 上有一个 BlockManager 存储模块
- 任务采用了数据本地性和推测执行等优化机制
RDD 的设计和运行原理
设计背景
矛盾:目前的 MapReduce 框架都是把中间结果写入到 HDFS 中,带来了大量的数据复制、磁盘 IO 和序列化开销
方法:提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同 RDD 之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘 IO 和序列化开销。
RDD 概念
一个 RDD 就是一个分布式对象集合,本质上是 一个只读的分区记录集合 ,每个 RDD 可以分成多个 分区 ,每个分区就是一个 数据集片段。
RDD 提供了一组丰富的操作以支持常见的数据运算,分为 行动(Action)和 转换(Transformation)两种类型,前者用于 执行计算并指定输出的形式 ,后者 指定 RDD 之间的相互依赖关系 。两类操作的主要区别是, 转换操作(比如 map、filter、groupBy、join 等)接受 RDD 并返回 RDD,而 行动操作(比如 count、collect 等)接受 RDD 但是返回非 RDD(即输出一个值或结果)。
RDD 典型的执行过程如下:
- RDD 读入外部数据源(或者内存中的集合)进行创建;
- RDD 经过一系列的“转换”操作,每一次都会产生不同的 RDD,供给下一个“转换”使用;
- 最后一个 RDD 经“行动”操作进行处理,并输出到外部数据源(或者变成 Scala 集合或标量)。
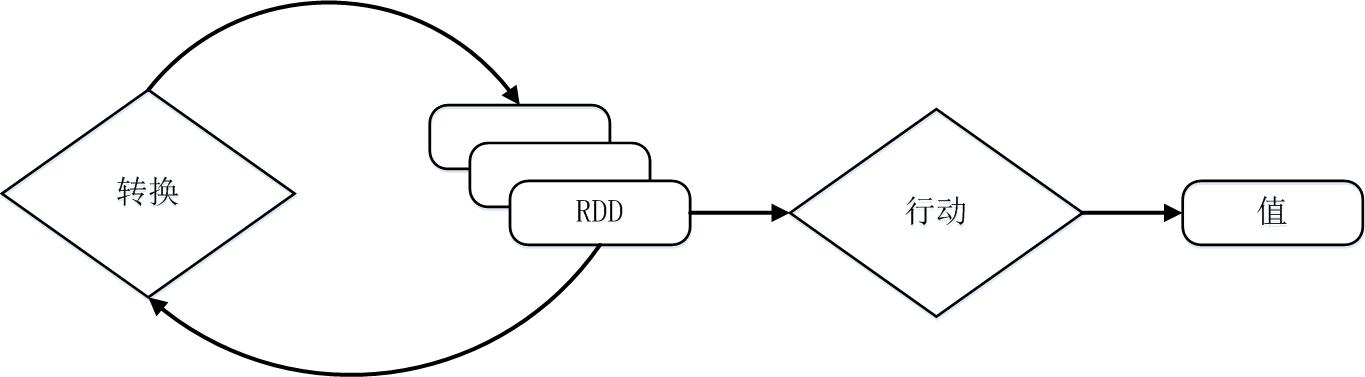
血缘关系(Lineage)
RDD 特性
- 高效的容错性
- 中间结果持久化到内存
- 存放的数据可以是 Java 对象,避免了不必要的对象序列化和反序列化开销
RDD 之间的依赖关系
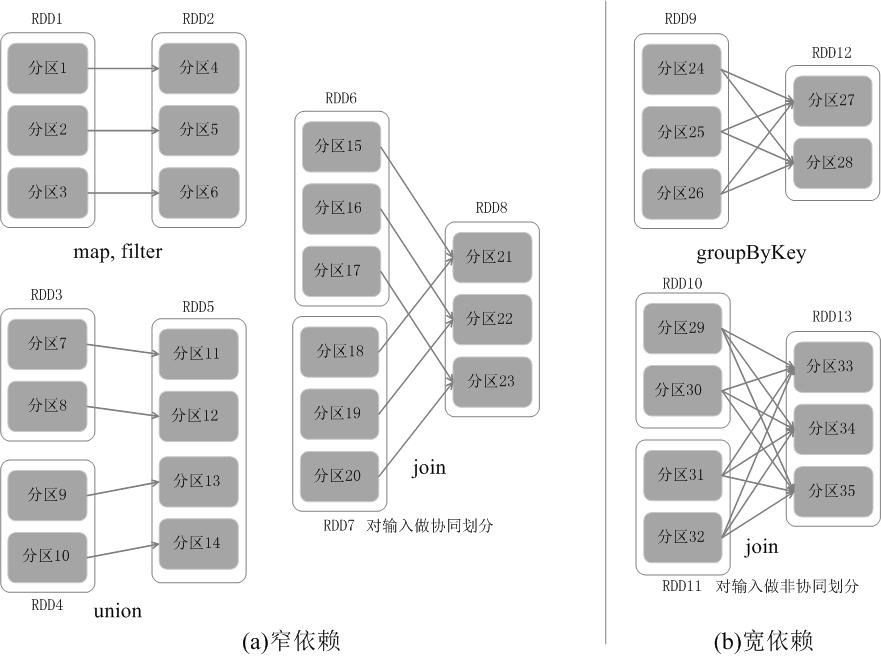
独生子女
如果父 RDD 的一个分区 只被一个子 RDD 的一个分区所使用 就是窄依赖,否则就是宽依赖。
窄依赖典型的操作包括 map、filter、union 等,宽依赖典型的操作包括 groupByKey、sortByKey 等。
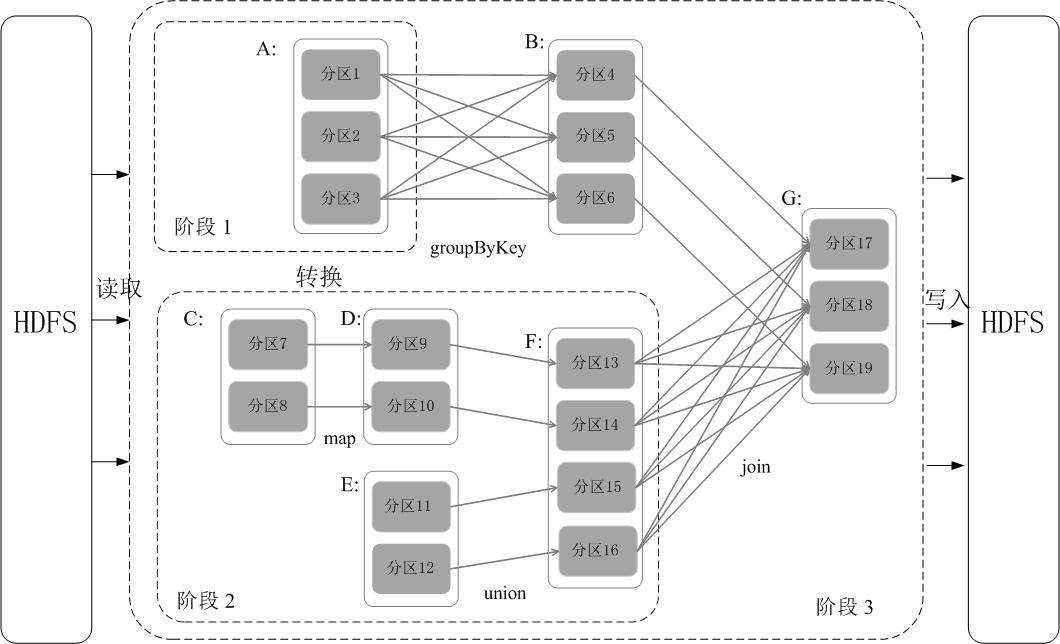
阶段的划分
具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算
RDD 运行过程
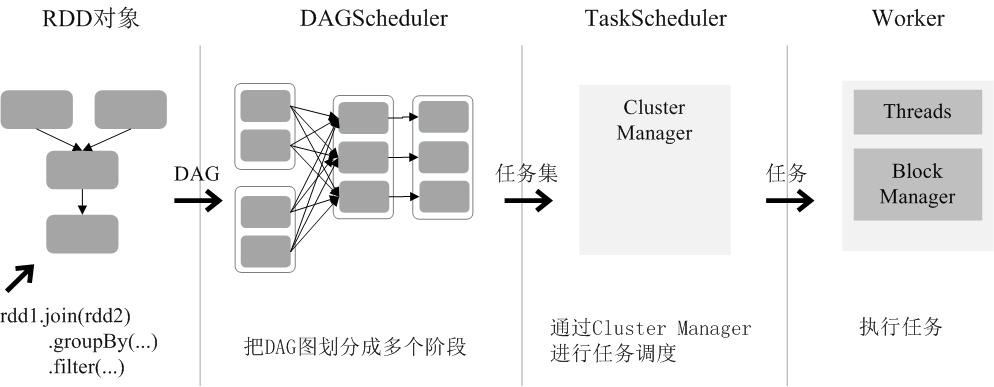
- 创建RDD 对象;
- SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG;
- DAG Scheduler 负责把 DAG 图分解成多个 阶段 ,每个阶段中包含了多个任务,每个 任务 会被任务调度器分发给各个 工作节点 (Worker Node)上的Executor 去执行。
部署模式
Spark 三种部署方式
standalone 模式
Spark 与 MapReduce1.0 完全一致,都是由一个 Master 和若干个 Slave 构成,并且以槽(slot)作为资源分配单位
Spark on Mesos 模式
Spark 官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
Spark on YARN 模式
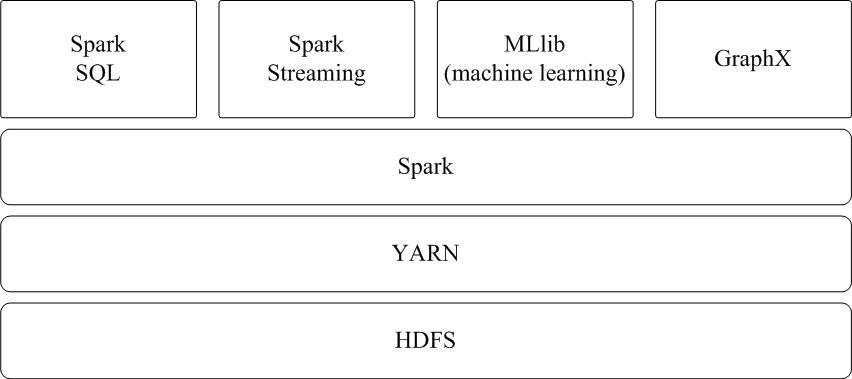
从“Hadoop+Storm”架构转向 Spark 架构
Hadoop+Storm 的架构(也称为 Lambda 架构)
Hadoop 负责对批量历史数据的实时查询和离线分析,而 Storm 则负责对流数据的实时处理。
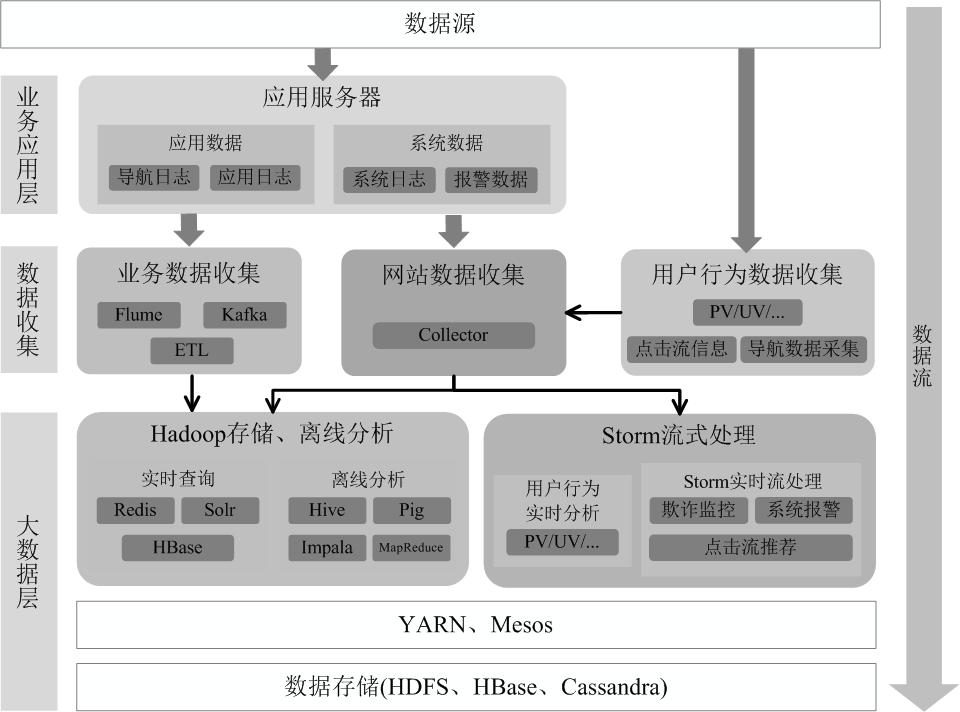
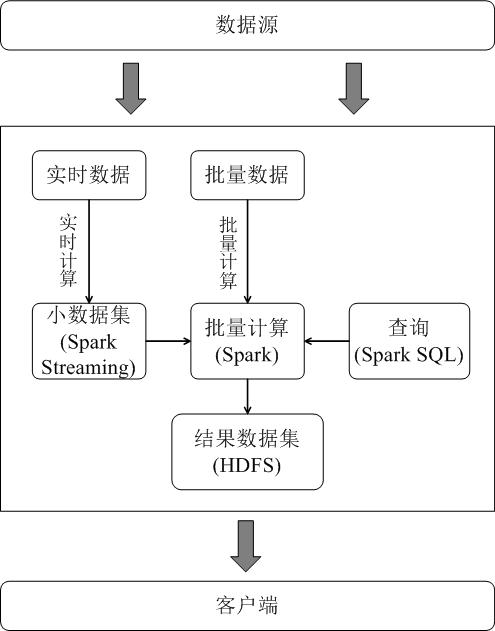
Hadoop 和 Spark 的统一部署